Syntactic parsing lies at the foundation of many natural-language processing applications. The term denotes the automatic extraction of a syntactic representation from a natural language text, usually in the form of a sequence of words and punctuation marks. The representation is designed to capture information about the elements‘ grammatical relations and functions. This output is traditionally used as a basis for higher-level tasks like grammar checking, semantic analysis, question answering and information extraction (Jurafsky and Martin, 2009, chapter 12).
One widely used description of syntax is so-called \textit{constituent structure}. Rooted in X-bar theory (Chomsky, 1970), the idea of constituency arises from the observation that groups of words can behave as single units (Jurafsky and Martin, 2009, chapter 12). Take for instance the noun phrases in (1.1).
(1.1)
a. the memory
b. a new computer
c. the person she really likes
Despite having completely different meanings, these three terms can occur in similar syntactic environments, for example before a verb as in (1.2).
(1.2)
a. the memory fades
b. a new computer arrives…
c. the person she really likes waits…
However, this is not true for all of the individual components of the phrases, as can be seen in (1.3). Therefore, one assumes the existence of an abstract category called a constituent to which one or more words can belong and for which rules like „noun phrases can be followed by verbs“ can be postulated (Jurafsky and Martin, 2009, chapter 12).
(1.3)
a. *the fades
b. *new arrives…
c. *likes spends…
Note: The asterisk marks constructions that are not grammatical.
Traditional views of constituency demand that constituents consist of adjacent words. This is rooted in a system for modelling languages called context-free grammar (CFG) (Chomsky, 1956), a generative device that derives sentences by using rewrite rules, starting with an initial symbol. The derivation path marks a hierarchy of constituents that can be arranged into a derivation/parse tree. Figure 1.1 gives an example for such a description. Note that the tree only contains non-crossing edges which is why it is called projective or continuous.
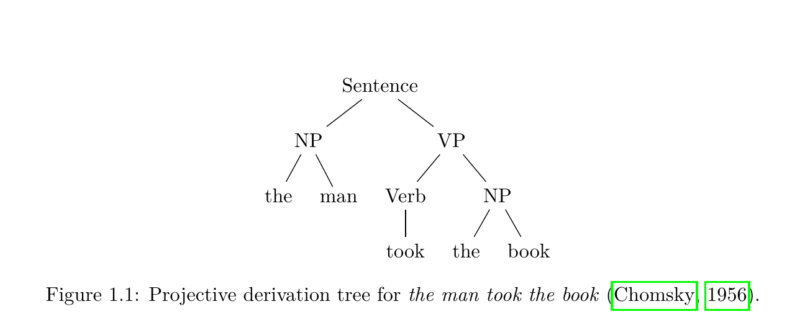
This view of constituency was adopted by many treebanks. Treebanks are linguistic corpora in which the sentences have been annotated with syntactic representations (e.g. constituency trees) (Jurafsky and Martin, 2009, chapter 12). However, this leads to difficulties when analysing syntactic phenomena that are believed to exhibit non-local dependencies. While the analysis of German or other languages with varying degrees of free word order evidently questions the projective approach, the English language also exhibits a fair amount of discontinuous phenomena, see (1.4) and (1.5).
(1.4)
a. sie packte ihre Werkzeuge ein
she packed her tools up
’she packed her tools‘
b. den Dank möchte ich nicht annehmen
the thanks want he not accept
‚he does not want to accept the thanks‘
c. ohne Scham scheinen sie das komplette Buffet aufgegessen zu haben
without shame seem they the complete buffet eaten to have
‚they seem to have eaten the entire buffet without shame‘
(1.5)
a. areas of the factory were particularly dusty where the crocidolite was used (Evang, 2011)
b. a man entered who was wearing a black suit (McCawley, 1982)
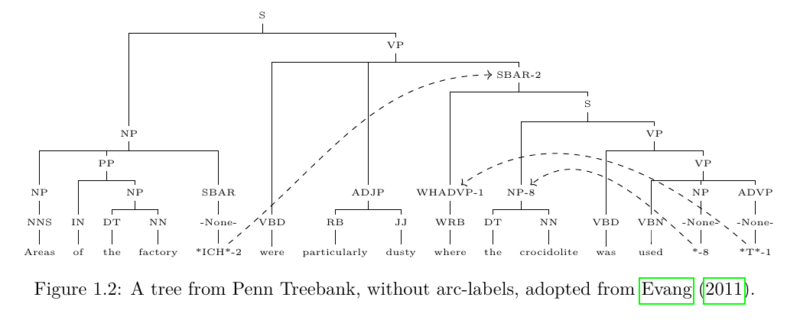
Some treebanks like the English Penn Treebank (Marcus et al., 1993) opted to mark discontinuous phenomena through indexing and trace nodes, i.e. empty nodes in the place where a discontinuous subsection of the sentence would be expected in „standard“ word order. This is motivated by the tradition of analysing discontinuities as instances of transformation or syntactic movement as introduced by Chomsky (1975). The tree in figure 1.2 features three cases of co-indexing. While such a strategy acknowledges the existence of discontinuous relationships, the long-range dependencies of the markers cannot be fully captured by traditional parsing techniques for projective grammars and often remain unused.
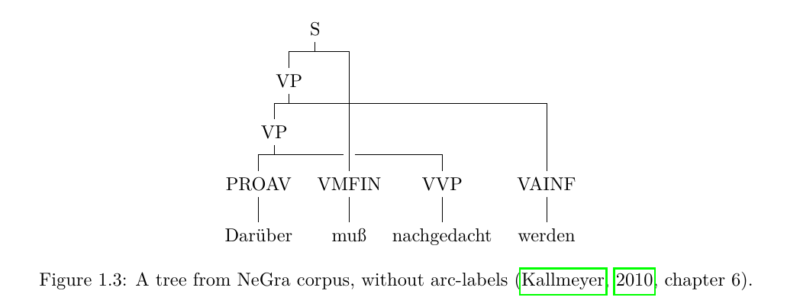
In a number of treebanks like the German NeGra (Skut et al., 1998) and TIGER treebanks (Brants et al., 2004) or English discontinuous Penn Treebank (Evang and Kallmeyer, 2011) (DPTB) long-range dependencies are represented by crossing edges and constituents with non-adjacent elements. The resulting trees are called discontinuous constituent trees. Figure 1.3 shows an example from the NeGra corpus.
In order to capture syntactic descriptions with discontinuous constituents, several formalisms have been proposed. Among these linear context-free rewriting systems (LCFRS) (Vijay-Shanker et al., 1987) have been shown to be a natural candidate for accurately covering the notion of discontinuous constituents employed by the aforementioned treebanks.
Being a foundation for many natural language processing tasks, parsing speed is a key concern and a driver of active research. Parsing LCFRS is non-trivial in terms of efficiency. The adaptation of traditional chart parsing for LCFRS results in a polynomial time complexity of O(n^(3*dim(G))) where n is the length of a sentence and dim(G) is the maximal number of discontinuous blocks of a constituent in the grammar. Transition-based parsing approaches aim at reducing this factor by doing away with the need for an explicit grammar. Instead, an artificial neural network is trained to produce discontinuous constituent trees given only raw text input using supervised learning on large annotated corpora. Errors in prediction are backpropagated through the network resulting in optimisations of its parameters. In this way, it implicitly learns to identify regularities that it can effectively use to predict trees for unseen data. A recent and elegant proposal for a neural stack-free transition-based parser developed by Coavoux and Cohen (2019) successfully allows for the derivation of any discontinuous constituent tree over a sentence in worst-case quadratic time.